Le problème de la répartition des tâches entre des agents en concurrence est un problème récurrent dans toute organisation.
Exemple: quatre personnes sont employées à temps partiel pour occuper un bureau 10 heures par semaine. Les heures d’ouverture du bureau doivent avoir lieu entre 9h et 19h du lundi au jeudi et entre 9h à 12h le vendredi. Une seule personne est nécessaire pour assurer le bon fonctionnement du bureau à une heure donnée, et les quatre employés ont des contraintes qui les empêchent de travailler à certaines heures de la journée.
Pour un être humain normalement constitué (autistes atteint du syndrome d’Asperger mis à part donc), trouver une organisation qui permet de satisfaire toutes ces contraintes relève du casse-tête. Et pas de chance, ce type de problème appartient au groupe des NP-complet; c’est à dire qu’il n’existe à l’heure actuel aucun algorithme permettant de trouver une solution optimale à un tel problème en un temps raisonnable. En revanche, il existe tout une classe d’algorithme permettant de trouver des solutions acceptables, et les algorithmes génétiques en font partie.
L’idée générale est la suivante (merci Wikipedia):

Structure de données.
Une seule structure nous importe: celle permettant de représenter une solution. Il faut garder à l’esprit que les solutions sont destinées à être recombinées afin d’en générer de nouvelles. Il faut donc que notre structure soit la plus simple possible afin que les croisements et les mutations que nous appliquerons ne soient pas trop complexes à implémenter. L’idéal est de travailler sur une structure à une dimension, c’est à dire un tableau. Si nous reprenons l’exemple de la répartition des heures d’ouverture entre nos quatre employés, nous pouvons imaginer la modélisation suivante: les indices de notre tableau représentent les différentes heures et ses éléments indiquent les numéros des employés de permanence.
Évaluation d’une solution (calcul du fitness).
Sans doute la partie la plus délicate, d’autant qu’il s’agit de prendre en compte différents critères d’efficacité. Toujours d’après l’exemple que j’ai exposé plus haut, nous savons que nous devons prendre en compte les contraintes suivantes:
- chaque employé doit travailler 10 heures dans la semaine.
- on a besoin que d’un employé par heure.
- certains employés ne peuvent pas travailler certaines heures de la journée.
- ouverture entre 9h et 19h du lundi au jeudi et entre 9h à 12h le vendredi.
Les contraintes 2 et 4 seront de toute façon respectées du fait de la structure de données que nous avons utilisé, nous pouvons donc les laisser de côté. Par contre il pourrait être intéressant de respecter les contraintes supplémentaires suivantes:
- il est préférable d’éviter les alternances bureau ouvert / bureau fermé dans la même journée.
- il est préférable que les heures de chaque employé soient regroupées pour leur éviter de nombreux aller-retour.
Si nous classons ces contraintes par ordre d’importance, nous avons:
- respect des heures impossibles à effectuer.
- quota des 10 heures.
- période de fermeture entre deux périodes d’ouverture dans la même journée.
- regroupement des heures pour un même employé.
Pour chaque solution, notre fonction d’évaluation devra comptabiliser les infractions de chacune de ces contraintes et appliquer un coefficient aux valeur ainsi calculées avant de les additionner. La pertinence d’une solution variera donc en sens inverse du résultat retourné par cette fonction.
L’application des coefficients est importante: c’est grâce à elle que notre algorithme saura qu’une solution affectant une heure de travail à un employé pourtant indisponible à ce moment là sera moins bonne qu’une autre solution qui fera fermer le bureau entre 14h et 15h le mardi par exemple. Les coefficients que j’ai utilisé sont calculés à l’aide de la formule: 100nombre de contraintes à prendre en compte (donc 4) – degrés d’importance de la contrainte (compris entre 1 et 4).
Sélection, croisement et mutation.
Internet fourmille de solutions toutes différentes les unes des autres. Leur implémentation ne pose aucun problème donc je ne les détaillerais pas ici. Pour cette article j’ai implémenté une sélection par rang, une mutation de type swap et un croisement tout personnel: deux parents donnent un enfant et chaque gêne des parents à une probabilité de 0.5 d’être attribué à l’enfant.
Architecture.
Les algorithmes génétiques peuvent être utilisés pour résoudre de très nombreux problèmes; l’idéal serait donc de pouvoir réutiliser les algorithmes que nous avons écrit. Il faut donc décrire les interfaces de chacune des structures et opérations réalisées (structure de donnée de type chromosome, évaluation, sélection, croisement et mutation). Seules la fonction d’évaluation ainsi que la structure chromosome devraient être modifiées pour que notre système puisse s’attaquer à d’autres problèmes.
Darwin: 1 – créationnisme: 0
Une population de départ générée aléatoirement, des sélections plus ou moins arbitraires, des croisements et des mutations qui se décident à coup de random… tout porte à croire que la mise en oeuvre d’un tel dispositif ne pourra jamais aboutir à une solution acceptable. Et comme une image vaut mieux que mille mots:
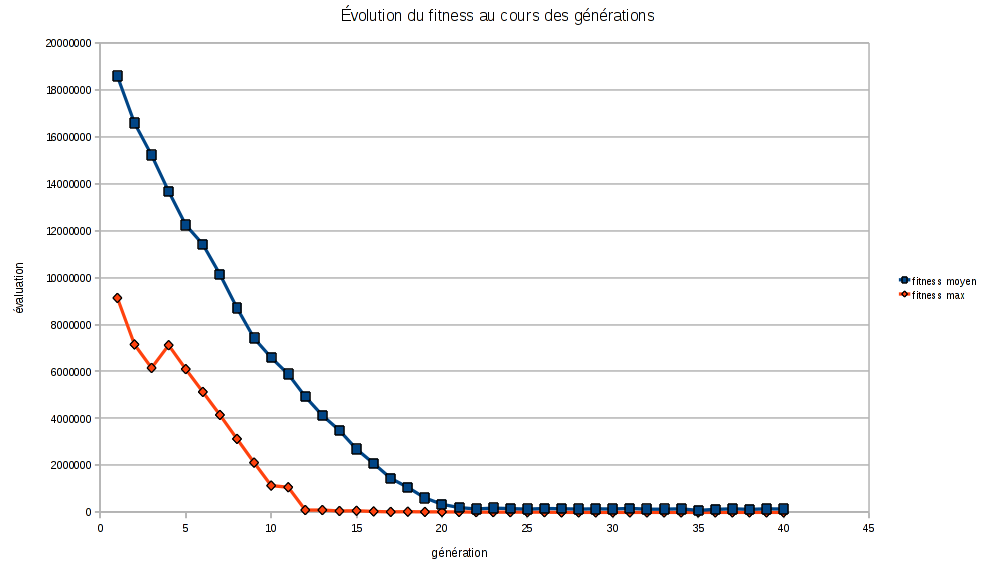
Les fitness moyen et optimal décroissent très rapidement (la taille de la population de départ est de 800 individus), cela signifie que les solutions générées sont de plus en plus pertinentes. Arrivé à la génération 25 on ne note plus de changement important (le fitness se stabilise autour de 20). Un fitness de 20 signifie que toutes les contraintes ont été respectées, et que les employés feront en moyenne des séances de travail de 2 heures.